
Le fine-tuning est rarement la bonne réponse en PME — RAG et prompt engineering couvrent 90% des cas, à 10x moins cher et 5x plus vite.
C'est ce qu'on observe systématiquement chez CZMultimedia : un dirigeant arrive convaincu qu'il a "besoin d'une IA entraînée sur ses données", devis d'un prestataire à 50 000 euros à l'appui. Dans la grande majorité des cas, on lui montre qu'un RAG bien construit à 5 000 euros donne le même résultat — parfois meilleur, parce qu'il reste à jour automatiquement.
Le problème n'est pas technique. Il est commercial : le mot "fine-tuning" sonne sérieux, technique, premium. Il rassure le décideur qui veut "vraiment industrialiser l'IA". Et il fait des marges confortables pour ceux qui le vendent. Sauf que dans 9 cas sur 10, le besoin réel se résout avec du prompt engineering propre ou un RAG bien câblé. Cet article démonte les 3 approches sans langue de bois, avec les coûts réels, les vrais cas où chacune est pertinente, et un tableau de décision actionnable.
- Une explication claire des 3 approches : prompt engineering, RAG, fine-tuning — sans jargon
- Un tableau de décision pour choisir selon ton cas réel
- Les coûts et délais réels (chiffres terrain, pas brochure commerciale)
- Un cas concret où le fine-tuning était justifié (rare, anonymisé)
- Pourquoi le fine-tuning est sur-vendu en France et comment ne pas se faire avoir
- Une checklist pour identifier la bonne approche en 5 minutes
Tu hésites entre les 3 approches sur ton projet IA ? Contactez-nous — on te dit honnêtement laquelle est la bonne.
Sommaire
- Les 3 approches en clair
- Tableau de décision : quel cas pour quelle approche
- Coûts et délais réels
- Cas terrain : un projet où le fine-tuning était justifié
- Pourquoi le fine-tuning est sur-vendu
- Combinaisons gagnantes : RAG + prompt, fine-tune + RAG
- Checklist : laquelle choisir ?
- FAQ
- Conclusion
Les 3 approches en clair
Avant de comparer, il faut comprendre ce que chaque approche fait réellement. Et surtout ce qu'elle ne fait pas.
Prompt engineering : changer ce que tu demandes
Le prompt engineering, c'est l'art d'écrire la bonne instruction au modèle. Tu ne touches ni au modèle, ni à tes données — tu joues uniquement sur la formulation, le contexte, les exemples (few-shot), le format de sortie attendu.
Concrètement, un bon prompt engineering ressemble à ça :
- Un rôle clair pour le modèle ("tu es un expert en…")
- Des contraintes explicites (format, longueur, ton)
- Des exemples (1 à 5) qui montrent le résultat attendu
- Une structure de réponse imposée (JSON, Markdown, sections)
- Des règles de comportement (que faire si tu ne sais pas, comment citer ses sources)
C'est l'approche la plus rapide, la moins chère, la plus testable. Et étonnamment puissante quand elle est bien faite. Un prompt de 200 lignes bien construit bat souvent un fine-tuning bâclé.
RAG : donner des données fraîches au modèle
RAG (Retrieval-Augmented Generation) ajoute une étape avant la génération : tu cherches dans tes documents les passages pertinents, tu les injectes dans le prompt, et le modèle répond en s'appuyant dessus. Le modèle ne "connaît" pas tes données — il les lit à chaque requête.
L'architecture classique :
- Tu indexes tes documents dans une base vectorielle (Qdrant, Pinecone, pgvector, Weaviate)
- À chaque requête utilisateur, tu cherches les 3-10 passages les plus pertinents
- Tu construis un prompt qui inclut la question + ces passages + des consignes
- Le modèle répond en citant les sources
Le RAG résout le problème majeur des LLM : ils ne connaissent pas tes données internes, et leurs connaissances générales sont figées à leur date d'entraînement. Avec un RAG, tu mets à jour ta base documentaire — l'IA suit en temps réel.
Pour un panorama complet sur cette approche, on a écrit un guide dédié sur le RAG en PME.
Fine-tuning : modifier le modèle lui-même
Le fine-tuning, c'est ré-entraîner partiellement un modèle pré-existant sur tes propres données. Tu prends un modèle de base (GPT-4o-mini, Llama 3, Mistral), tu lui fournis un dataset de paires (input, output), et tu l'entraînes pour qu'il apprenne ton style, ton format, ton vocabulaire métier.
Ce que le fine-tuning fait bien :
- Apprendre un format de sortie très spécifique et stable
- Internaliser un ton, un style, un vocabulaire métier
- Optimiser des tâches répétitives très cadrées (classification fine, transcription spécialisée)
- Réduire la longueur des prompts une fois le comportement appris
Ce que le fine-tuning ne fait pas bien :
- Apporter des connaissances factuelles fraîches (le RAG est meilleur pour ça)
- Garantir l'absence d'hallucination (le modèle invente quand même)
- Être maintenu facilement (chaque évolution du dataset = nouvel entraînement)
- Être compétitif coûts/délais sur un cas standard
Le fine-tuning n'apprend pas des connaissances, il apprend des comportements. Si ton besoin c'est "que l'IA connaisse mon catalogue produit", le fine-tuning est le mauvais outil — un RAG est plus adapté, plus rapide à mettre à jour, et beaucoup moins cher. Le fine-tuning, c'est pour apprendre à l'IA comment répondre, pas quoi répondre.
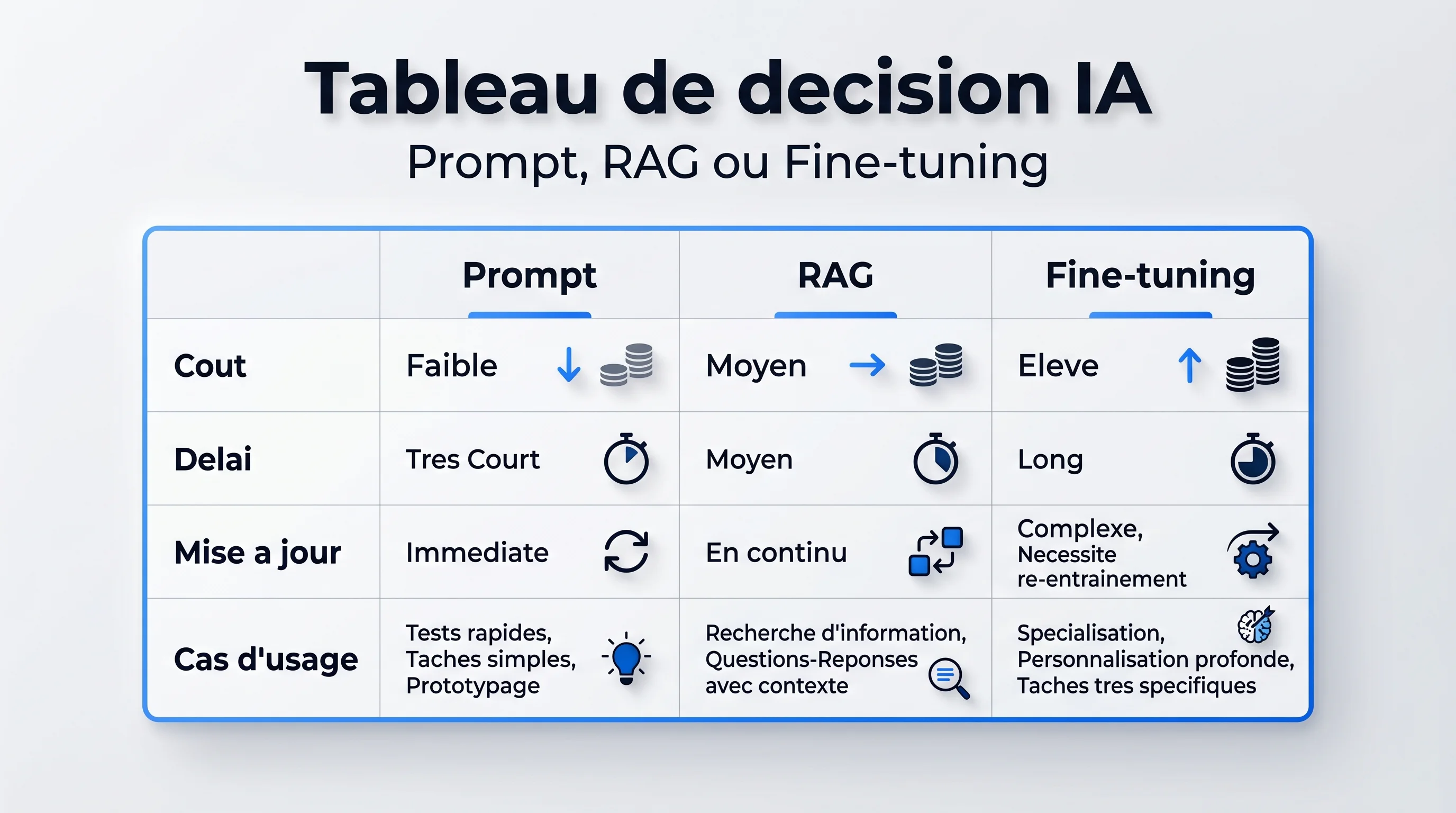
Tableau de décision : quel cas pour quelle approche
Voici la grille qu'on utilise en interne pour orienter un projet en 5 minutes. Chaque ligne = un besoin réel, chaque colonne = la réponse adaptée.
| Ton besoin réel | Prompt engineering | RAG | Fine-tuning |
|---|---|---|---|
| L'IA doit connaître ma documentation interne | OUI | ||
| L'IA doit répondre à partir de mes données client (CRM) | OUI | ||
| L'IA doit suivre un format de sortie très précis et stable | OUI | parfois | |
| L'IA doit adopter le ton de ma marque | OUI | parfois | |
| L'IA doit classer des emails en 50 catégories métier précises | OUI | ||
| L'IA doit transcrire un vocabulaire technique très spécialisé | OUI | ||
| L'IA doit résumer des documents long format | OUI | OUI | |
| L'IA doit citer ses sources | OUI | ||
| L'IA doit s'appuyer sur des données qui changent toutes les semaines | OUI | ||
| L'IA doit fonctionner offline (on-premise, pas d'API externe) | OUI | OUI | |
| L'IA doit traiter des dizaines de millions de tokens à coût réduit | OUI |
La règle simple
Pose-toi 3 questions dans cet ordre :
- Est-ce qu'un meilleur prompt suffirait ? Souvent oui. Tu n'as juste pas encore essayé sérieusement.
- Sinon, est-ce que le besoin est de connaître mes données ? RAG.
- Sinon, est-ce que le besoin est un comportement très spécifique, répété des millions de fois ? Fine-tuning.
Si tu hésites entre les 3, c'est presque toujours qu'il faut commencer par les 2 premiers. Le fine-tuning sans avoir épuisé les autres options, c'est tirer au bazooka sur un moustique — et payer les 50 000 euros qui vont avec.
Coûts et délais réels
Les ordres de grandeur qu'on observe en France, sur des projets PME, en 2025-2026. Ce ne sont pas des prix gravés — la complexité du dataset, le périmètre fonctionnel, et la qualité visée changent tout. Mais ça donne une lecture honnête.
Prompt engineering
- Coût : 1 000 à 5 000 euros pour un prompt de production (audit, itérations, tests, documentation)
- Délai : 3 jours à 2 semaines
- Compétences : un consultant qui comprend ton métier + sait écrire des prompts structurés
- Maintenance : faible — quelques itérations par trimestre quand le besoin évolue
- Coût récurrent : uniquement les tokens API consommés
C'est l'approche par défaut. Si tu n'as jamais sérieusement essayé d'optimiser tes prompts, tu n'as pas le droit moral de passer aux étapes suivantes.
RAG
- Coût initial : 5 000 à 25 000 euros selon la complexité (volume de documents, qualité du chunking, ré-ranking, évaluation)
- Délai : 2 à 6 semaines pour un MVP en production
- Compétences : un dev backend qui maîtrise les bases vectorielles + le métier qui structure le corpus
- Maintenance : modérée — réindexation périodique, ajustement des paramètres de retrieval
- Coût récurrent : tokens API + hébergement de la base vectorielle (50 à 500 euros/mois selon le volume)
C'est l'approche qu'on recommande dans la majorité des projets de PME où l'IA doit s'appuyer sur des données internes.
Fine-tuning
- Coût initial : 20 000 à 80 000 euros pour un projet sérieux (curation dataset = 60-70% du budget, entraînement = 5-10%, évaluation et déploiement = 25-30%)
- Délai : 2 à 4 mois entre cadrage et mise en production stable
- Compétences : un ML engineer + un expert métier disponible des dizaines d'heures pour la curation
- Maintenance : lourde — chaque évolution majeure du besoin nécessite un nouveau cycle d'entraînement
- Coût récurrent : hébergement du modèle si auto-hébergé (GPU 24/7) ou tarif fine-tuned API (souvent 2 à 8x le tarif standard)
Beaucoup de PME paient un fine-tuning à 50 000 euros sur un cas où un RAG à 8 000 euros aurait fait pareil. Le piège : un prestataire qui propose directement le fine-tuning sans avoir cadré sérieusement l'alternative. Avant de signer, exige un comparatif documenté RAG vs fine-tuning sur ton cas, avec un POC RAG d'abord. Si le prestataire refuse, c'est un signal.
Tu as un devis fine-tuning sur la table et tu veux un avis honnête ? Contactez-nous — on te dit en 30 minutes si c'est cohérent.
Cas terrain : un projet où le fine-tuning était justifié
Pour être juste, voici un cas où le fine-tuning était vraiment la bonne réponse. C'est rare, mais ça existe — et ça permet de comprendre les vrais critères de pertinence.
Le contexte
Un éditeur de logiciel médical (PME, 60 collaborateurs, secteur santé) intégrait dans son produit un module de transcription assistée de comptes-rendus médicaux. Les médecins utilisateurs dictaient leurs comptes-rendus, l'IA les structurait selon un format normé propre au métier (anatomopathologie spécifique).
Le besoin : transcrire un audio en compte-rendu structuré avec :
- Un vocabulaire technique très spécialisé (15 000+ termes médicaux propres au domaine)
- Une structure de document strictement normée (sections obligatoires, ordre fixe, terminologie contrôlée)
- Un volume cible massif : plusieurs millions de transcriptions par an
- Une exigence de précision élevée (les erreurs de terminologie ont des conséquences cliniques)
Pourquoi RAG seul ne suffisait pas
On a commencé par un POC RAG sur Whisper + GPT-4 avec un dictionnaire métier injecté en contexte. Résultat : précision correcte sur les termes courants, mais le modèle hallucinait régulièrement sur les termes rares, et la structure du compte-rendu n'était pas stable malgré un prompt très détaillé.
Le problème de fond : le modèle n'avait jamais vu ce type de structure et de terminologie pendant son entraînement. Lui injecter 50 exemples en contexte ne suffisait pas — il fallait qu'il internalise le format.
Pourquoi le prompt engineering ne suffisait pas
On a poussé le prompt à 800 lignes avec des dizaines d'exemples few-shot. Gain marginal. Le coût par requête explosait (tokens d'entrée énormes), la latence devenait inacceptable pour un usage temps réel, et la stabilité du format restait insuffisante (95% de conformité quand on en visait 99,5%).
La solution fine-tuning
On a fine-tuné un modèle open source de taille moyenne (Llama 3 70B) sur un dataset curé :
- 50 000 paires (audio transcrit brut, compte-rendu structuré final) constituées sur 4 mois avec 3 médecins experts
- Une étape de validation par double relecture sur 20% du dataset
- Un protocole d'évaluation métier (pas juste BLEU/ROUGE) défini avec les utilisateurs cibles
Les résultats
- Précision sur la terminologie spécialisée : +12 points par rapport au RAG seul
- Conformité structurelle : 99,7% (vs 95% en RAG/prompt avancé)
- Coût d'inférence : divisé par 3 (prompts beaucoup plus courts, modèle hébergé)
- Latence : divisée par 2
Les vrais chiffres
- Budget total : ~30 000 euros (curation dataset = 70%, entraînement et évaluation = 20%, intégration = 10%)
- Durée : 3 mois de bout en bout
- ROI : amorti en 8 mois sur les économies d'infrastructure et la qualité produit
Pourquoi ce cas justifiait le fine-tuning
Quatre critères réunis, ce qui est rare :
- Volume massif (millions de requêtes/an) qui amortit le coût initial
- Vocabulaire ultra-spécialisé absent de l'entraînement de base des LLM
- Format de sortie stable et critique (la structure ne change pas)
- Données disponibles en quantité (50k paires curables avec un effort raisonnable)
Si un seul de ces 4 critères avait manqué, on aurait recommandé un RAG enrichi. C'est cette grille à 4 critères qu'on applique aujourd'hui à tous les briefs où le client demande du fine-tuning.
Pourquoi le fine-tuning est sur-vendu
Le mot "fine-tuning" rassure. Il sonne technique, sérieux, premium. Et il fait vendre. Voici pourquoi tu en entends parler partout — et pourquoi c'est un biais commercial avant d'être un choix technique.
Les intérêts qui poussent au fine-tuning
Les prestataires : un projet fine-tuning facture 5 à 10 fois plus qu'un RAG. Marges plus confortables, prestation plus longue, justifications techniques plus complexes (donc moins challengeable par le client).
Les fournisseurs cloud : OpenAI, Google, AWS, Azure proposent tous des offres fine-tuning. Ça consomme du GPU, ça crée du lock-in (un modèle fine-tuné chez un fournisseur n'est pas portable), et le tarif d'inférence post-fine-tuning est plus élevé. Tout le monde y gagne — sauf le client.
Les médias tech : "fine-tuning" fait des titres plus accrocheurs que "prompt engineering". Le storytelling autour de "l'IA entraînée sur tes données" est plus vendeur que "on a écrit un bon prompt".
Les arguments commerciaux à challenger
| Argument vendeur | Réalité |
|---|---|
| "Avec le fine-tuning, l'IA connaîtra vraiment vos données" | Faux. Le fine-tuning apprend des comportements, pas des connaissances. Pour les connaissances, c'est le RAG. |
| "C'est plus sécurisé, vos données ne sortent pas" | À vérifier. Si tu fine-tunes via l'API OpenAI, tes données passent par OpenAI. Pour ne rien laisser sortir, il faut auto-héberger un modèle open source. |
| "C'est plus performant" | Ça dépend de la métrique. Sur la qualité métier, souvent oui sur des cas spécifiques. Sur la fraîcheur des données et la flexibilité, le RAG gagne. |
| "C'est l'avenir de l'IA d'entreprise" | Cliché marketing. L'avenir est dans la combinaison des 3 approches selon le besoin, pas dans le tout-fine-tuning. |
Le bon réflexe
Avant d'accepter un devis fine-tuning, exige systématiquement :
- Un comparatif documenté prompt engineering vs RAG vs fine-tuning sur ton cas
- Un POC RAG (2-3 semaines, budget contenu) avant de t'engager sur le fine-tuning
- Des métriques d'évaluation métier (pas juste des benchmarks NLP génériques)
- Une explication claire de la stratégie de mise à jour (ré-entraînement périodique = quand, comment, à quel coût)
Si le prestataire ne peut pas répondre à ces 4 points, c'est qu'il vend un produit, pas une solution à ton problème.
Combinaisons gagnantes : RAG + prompt, fine-tune + RAG
Les 3 approches ne s'excluent pas. Les architectures les plus matures les combinent intelligemment, chacune sur sa zone de compétence.
Combo 1 : prompt engineering + RAG (le plus fréquent)
C'est l'architecture par défaut sur 80% des projets d'automatisation IA que nous mettons en place. Le RAG fournit les données, le prompt engineering structure la réponse, le format de sortie, le ton, les garde-fous.
Concrètement :
- Le RAG récupère 5-10 passages pertinents dans tes documents
- Le prompt définit le rôle, le format, les règles ("cite tes sources", "réponds en JSON", "si tu ne sais pas, dis-le")
- Le modèle (GPT-4o, Claude Sonnet, ou un open source) génère la réponse
Coût total : 5 000 à 20 000 euros. Délai : 3 à 6 semaines. C'est le rapport qualité/prix imbattable pour la majorité des cas PME.
Combo 2 : fine-tuning + RAG (les cas avancés)
Quand tu as à la fois besoin d'un comportement spécifique et de données fraîches, tu combines :
- Le fine-tuning apprend au modèle le format, le ton, le vocabulaire métier, la structure attendue
- Le RAG apporte les données fraîches à chaque requête
Cas typique : un assistant juridique qui doit répondre dans le style et la structure d'un avocat (fine-tuning) en s'appuyant sur la base documentaire à jour des dernières jurisprudences (RAG). Aucune des 2 approches seule ne donne le résultat.
Coût total : 40 000 à 100 000 euros. Délai : 4 à 6 mois. Réservé aux cas où le ROI est démontrable à 7 chiffres.
Combo 3 : prompt engineering seul (les cas simples)
À ne pas négliger : beaucoup de cas se résolvent avec uniquement un bon prompt engineering, surtout sur des modèles à très grande fenêtre de contexte (Claude Sonnet 4 et au-delà, Gemini Pro). Tu mets ta documentation entière en contexte, tu structures un prompt solide, et c'est plié.
C'est viable quand :
- Tes documents tiennent dans la fenêtre de contexte (jusqu'à plusieurs centaines de milliers de tokens)
- Le coût par requête reste acceptable (pas des millions de requêtes/jour)
- La latence n'est pas critique
Coût : 1 000 à 5 000 euros. Délai : quelques jours. Sous-estimé.
Commence par le plus simple. Tu passes au suivant uniquement quand tu as prouvé que le précédent ne suffisait pas. Prompt engineering → RAG → RAG + prompt avancé → RAG + fine-tuning. Sauter directement à l'étape 4 sans avoir validé les 3 premières, c'est jeter l'argent par la fenêtre.
Checklist : laquelle choisir ?
Cette checklist t'aide à orienter ton projet en 5 minutes. Coche les items qui correspondent à ton cas, le profil dominant te donne la réponse.
Profil prompt engineering : ton besoin tient en quelques règles claires + tu n'as pas besoin de connaissances spécifiques externes au modèle
Profil prompt engineering : tu n'as pas encore audité sérieusement tes prompts actuels — il y a probablement 50% de gain immédiat à aller chercher
Profil prompt engineering : ton volume est faible (centaines à milliers de requêtes/mois) et tu veux itérer vite
Profil RAG : ton IA doit s'appuyer sur ta documentation interne (procédures, FAQ, base de connaissances)
Profil RAG : tes données changent régulièrement (catalogue, prix, stocks, jurisprudence, articles)
Profil RAG : tu as besoin que l'IA cite ses sources (contexte réglementaire, juridique, médical)
Profil RAG : tu connectes l'IA à plusieurs sources (CRM, Notion, Drive, base SQL) — un agent multi-RAG est souvent la bonne réponse
Profil fine-tuning : tu as un volume massif de requêtes répétitives (millions/an) qui amortissent l'investissement
Profil fine-tuning : ton domaine utilise un vocabulaire spécialisé absent des LLM standards (médical pointu, juridique très technique, industrie ultra-spécialisée)
Profil fine-tuning : tu disposes ou peux constituer un dataset propre de plusieurs milliers de paires (input, output) de qualité
Profil fine-tuning : tu as besoin d'un format de sortie très stable et critique (conformité réglementaire, intégration aval rigide)
Profil combo RAG + fine-tuning : tu coches au moins 2 critères de fine-tuning ET au moins 2 critères de RAG — les deux dimensions sont nécessaires
Si tu coches majoritairement les 3 premiers items : prompt engineering, démarre là, mesure, itère.
Si tu coches majoritairement les items 4-7 : RAG, c'est ton sweet spot. Probablement 80% des cas PME.
Si tu coches au moins 3 des items 8-11 : fine-tuning mérite une analyse sérieuse. Pas avant.
Si tu hésites encore après cette checklist, l'erreur la plus coûteuse n'est pas de choisir l'approche A ou B, c'est d'investir 50 000 euros dans la mauvaise direction. Un cadrage de 30 minutes avec quelqu'un qui a déjà livré les 3 approches t'évite cette erreur.
Et avant de te lancer, vérifie aussi que ton infrastructure tient le choc — un RAG ou un agent IA sur un site lent ou mal monté hérite des problèmes existants. Si la performance est un sujet, on a écrit un guide complet sur l'amélioration de la performance des sites web qui couvre les bases techniques.
FAQ
Questions fréquentes

Conclusion
Le fine-tuning n'est pas un mauvais outil. C'est un outil mal utilisé dans 9 cas sur 10 en PME, parce qu'il est sur-vendu commercialement et mal compris techniquement.
Ce qu'il faut retenir :
- Le prompt engineering bat souvent le fine-tuning quand il est fait sérieusement — c'est l'approche par défaut, pas une option de second rang
- Le RAG couvre la majorité des besoins PME où l'IA doit s'appuyer sur tes données : moins cher, plus rapide, et mis à jour automatiquement
- Le fine-tuning a sa place sur des cas précis : volume massif, vocabulaire ultra-spécialisé, format critique, dataset disponible — les 4 critères doivent être réunis
- Les combinaisons gagnent presque toujours : prompt + RAG est le standard, fine-tune + RAG pour les cas avancés
- Avant de signer un devis fine-tuning, exige un POC RAG comparé et un comparatif documenté sur ton cas — c'est le réflexe qui te fait économiser des dizaines de milliers d'euros
Chez CZMultimedia, on accompagne les PME de la région lyonnaise et au-delà sur des projets d'automatisation IA et d'intelligence artificielle sur mesure avec une règle simple : on choisit l'approche en fonction de ton cas réel, pas de notre marge. On commence toujours par challenger le besoin, valider la simplicité, et ne complexifier qu'à preuve nécessaire.
Contactez-nous pour un cadrage en 30 minutes — réponse sous 24h, sans engagement, et on te dit honnêtement laquelle des 3 approches est faite pour toi.
Vous voulez savoir si votre site peut vraiment générer plus de clients ?
J’aide les PME à améliorer leur site web et leurs projets digitaux pour générer plus de demandes clients.
Je vous propose un audit gratuit, rapide et sans engagement.
Sans engagement • Recommandations concrètes • Réponse sous 24h